hadoop 2.7.1
编译安装
编译安装 hadoop 2.7.1
下载文件
jdk-7u80-linux-x64.tar.gz
hadoop-2.7.1-src.tar.gz
protobuf-2.5.0.tar.gz
apache-ant-1.9.6-bin.tar.gz
cmake-3.4.2-Linux-x86_64.tar.gz
apache-maven-3.3.9-bin.tar.gz
findbugs-noUpdateChecks-3.0.1.tar.gz
yum 安装依赖
1
yum -y install lzo-devel zlib-devel gcc autoconf automake libtool glibc-headers gcc-c++ openssl-devel
编译 protobuf
1
2
3
4
5cd protobuf-2.5.0
./configure
make
make check
make install解压文件,设置环境变量
1
2
3
4
5
6
7
8
9tar -zxvf *
vim /etc/profile
export JAVA_HOME=/usr/java
export PATH=$JAVA_HOME/bin:$PATH
export MAVEN_HOME=/root/soft/apache-maven-3.3.9
export CMAKE_HOME=/root/soft/cmake-3.4.2-Linux-x86_64
export FINDBUGS_HOME=/root/soft/findbugs-3.0.1
export ANT_HOME=/root/soft/apache-ant-1.9.6
export PATH=$PATH:$MAVEN_HOME/bin:$CMAKE_HOME/bin:$FINDBUGS_HOME/ bin:$ANT_HOME/bin
使环境变量生效
1
source /etc/profile
进入 hadoop 目录
1
cd hadoop-2.7.1-src
mvn 编译代码(自动下载 maven 依赖,消耗时间过长)
1
mvn clean package -DskipTests -Pdist,native,docs -Dtar
注意:编译完成需要消耗 6.5G 硬盘

启动 Hadoop
方案:
准备 hd201 hd202 hd205 hd206 hd207 hd208 hd209 hd210 8 台机器
分别配置各自 hostname,hosts 文件
配置 ssh 免密码登录
hd201 hd202 运行 NameNode ResourceManager
hd205 hd206 hd207 运行 DataNode NodeManager
hd208 hd209 hd210 运行 zookeeper JournalNode
ssh 免密码登录
生成公私钥
1 | ssh-keygen |
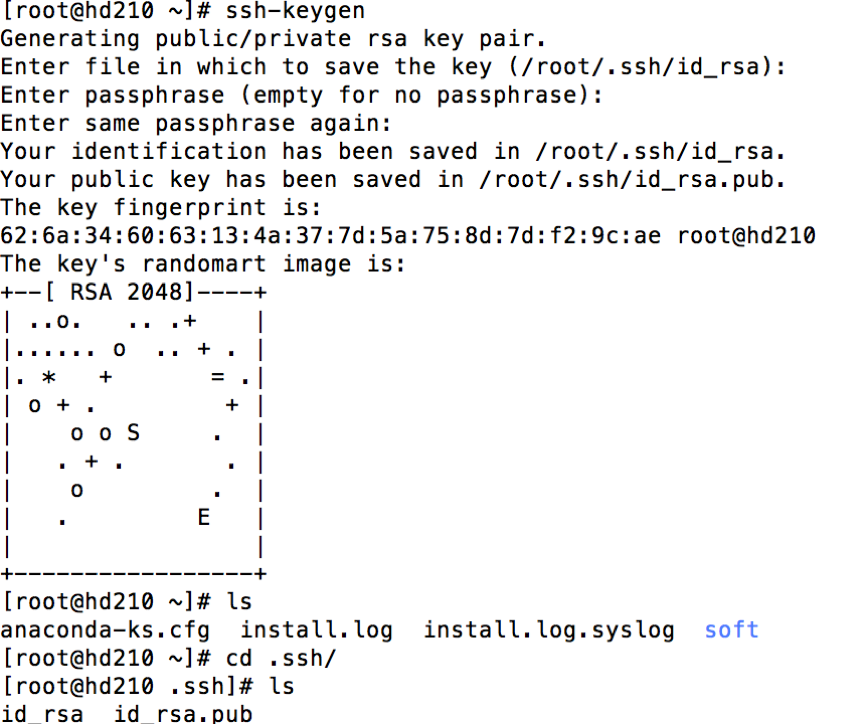
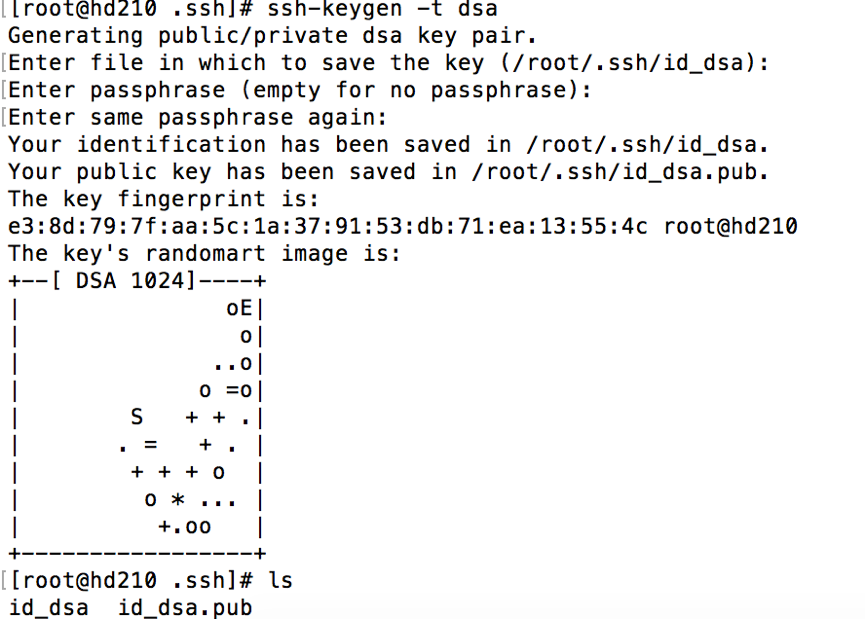
默认使用 rsa,可以加参数 -t dsa
复制 id_rsa.pub 里的内容到 ~/.ssh/authorized_keys
1 | cd ~/.ssh |
修改 authorized_keys 权限为 644
1 | chmod 644 authorized_keys |

复制斜公钥到其它机器
1 | ssh-copy-id -i hd202 |
配置各机器 hostname
1 | vim /etc/sysconfig/network |
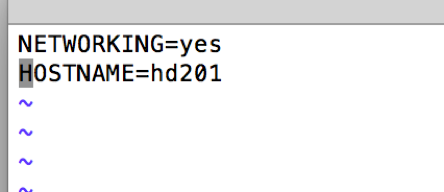
配置/etc/hosts
1 | 192.168.1.201 hd201 |
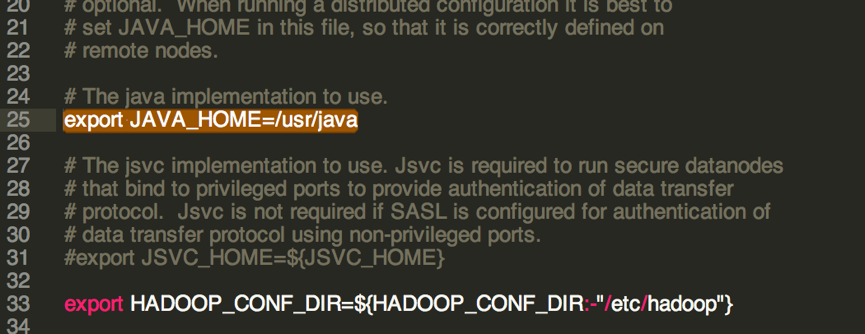
配置 hadoop-env.sh
1 | export JAVA_HOME=/usr/java |
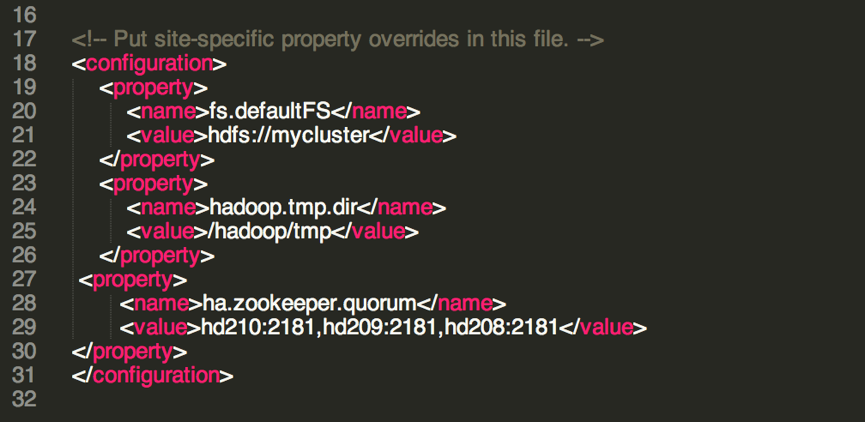
配置 core-site.xml
1 | <configuration> |
配置 hdfs-site.xml
1 | <configuration> |
取消文件权限控制(在 hdfs-site.xml 中添加),可以不加,使用-DHADOOP_USER_NAME=root 启动应用程序
1 | <property> |
配置 datanode 的配置文件 slaves
1 | vim slaves |
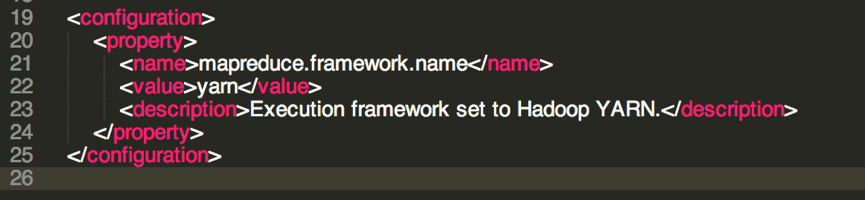
配置 mapreduce 文件 mapred-site.xml
默认是没有 mapred-site.xml 文件的,里面有一个 mapred-site.xml.example,重命名为 mapred-site.xml
1 | mv mapred-site.xml.example mapred-site.xml |
配置内容如下,这里就是指明 mapreduce 是用在 YARN 之上来执行的。
1 | <configuration> |
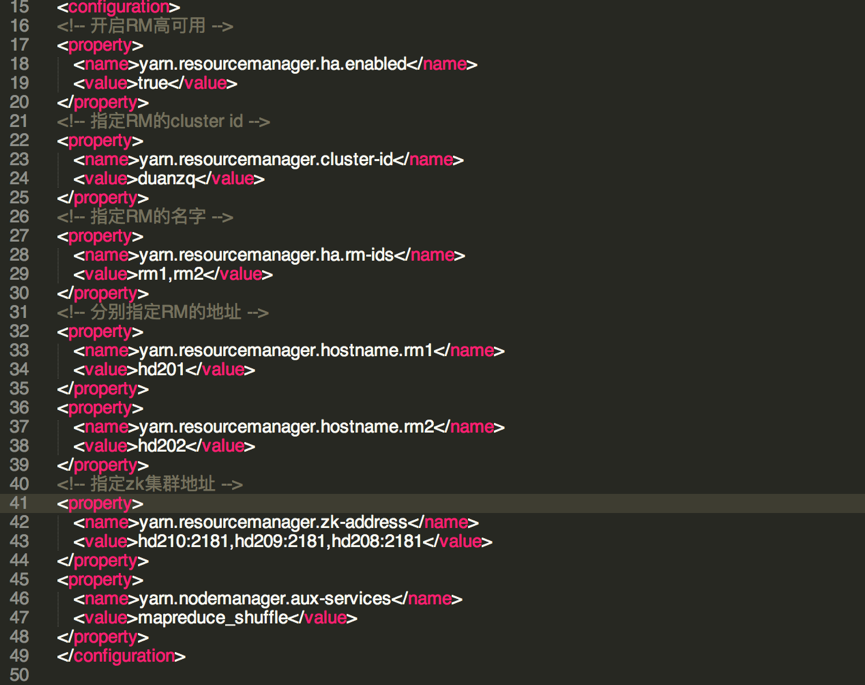
配置 yarn-site.xml
1 | <configuration> |
将 hadoop 复制到其它节点
1 | scp -r /hadoop hd202:/ |
启动 zookeeper
启动 hd208,hd209,hd210 三台机器上的 zookeeper
在 hd201 上启动 journalnode
1 | sbin/hadoop-daemons.sh start journalnode |
在 hd208,hd209,hd210 上会启动 journalnode 节点
QuorumPeerMain 是 zookeeper
在 hd201 上格式化 hadoop
1 | hadoop namenode -format |
格式化后会在根据 core-site.xml 中的 hadoop.tmp.dir 配置生成个文件,在 hd201 中会出现一个 tmp 文件夹,/hadoop/tmp,现在规划的是 hadoop01 和 hadoop02 是 NameNode,然后将/soft/hadoop-2.7.1/tmp 拷贝到 hadoop02:/soft/hadoop-2.7.1/下,这样 hd202 就不用格式化了。
1 | scp -r /hadoop/tmp hd202: /hadoop/ |
在 hd201 上格式化 ZK
1 | hdfs zkfc -formatZK |
在 hd201 上启动 HDFS
1 | sbin/start-dfs.sh |
在 hd201 上启动 YARN
1 | sbin/start-yarn.sh |
单独启动 NameNode
1 | sbin/hadoop-daemon.sh start namenode |
单独启动 ResourceManager
1 | sbin/yarn-daemon.sh start resourcemanager |
访问 url
192.168.1.201:50070
192.168.1.201:8088/
启动 historyserver
1 | sbin/mr-jobhistory-daemon.sh start historyserver |
192.168.1.201:19888
参考地址
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ClusterSetup.html
各端口说明
Hadoop 集群的各部分一般都会使用到多个端口,有些是 daemon 之间进行交互之用,有些是用于 RPC 访问以及 HTTP 访问。而随着 Hadoop 周边组件的增多,完全记不住哪个端口对应哪个应用,特收集记录如此,以便查询。
这里包含我们使用到的组件:HDFS, YARN, HBase, Hive, ZooKeeper:
| 组件 | 节点 | 默认端口 | 配置 | 用途说明 |
|---|---|---|---|---|
| HDFS | DataNode | 50010 | dfs.datanode.address | datanode 服务端口,用于数据传输 |
| HDFS | DataNode | 50075 | dfs.datanode.http.address | http 服务的端口 |
| HDFS | DataNode | 50475 | dfs.datanode.https.address | https 服务的端口 |
| HDFS | DataNode | 50020 | dfs.datanode.ipc.address | ipc 服务的端口 |
| HDFS | NameNode | 50070 | dfs.namenode.http-address | http 服务的端口 |
| HDFS | NameNode | 50470 | dfs.namenode.https-address | https 服务的端口 |
| HDFS | NameNode | 8020 | fs.defaultFS | 接收 Client 连接的 RPC 端口,用于获取文件系统 metadata 信息。 |
| HDFS | journalnode | 8485 | dfs.journalnode.rpc-address | RPC 服务 |
| HDFS | journalnode | 8480 | dfs.journalnode.http-address | HTTP 服务 |
| HDFS | ZKFC | 8019 | dfs.ha.zkfc.port | ZooKeeper FailoverController,用于 NN HA |
| YARN | ResourceManager | 8032 | yarn.resourcemanager.address | RM 的 applications manager(ASM)端口 |
| YARN | ResourceManager | 8030 | yarn.resourcemanager.scheduler.address | scheduler 组件的 IPC 端口 |
| YARN | ResourceManager | 8031 | yarn.resourcemanager.resource-tracker.address | IPC |
| YARN | ResourceManager | 8033 | yarn.resourcemanager.admin.address | IPC |
| YARN | ResourceManager | 8088 | yarn.resourcemanager.webapp.address | http 服务端口 |
| YARN | NodeManager | 8040 | yarn.nodemanager.localizer.address | localizer IPC |
| YARN | NodeManager | 8042 | yarn.nodemanager.webapp.address | http 服务端口 |
| YARN | NodeManager | 8041 | yarn.nodemanager.address | NM 中 container manager 的端口 |
| YARN | JobHistory Server | 10020 | mapreduce.jobhistory.address | IPC |
| YARN | JobHistory Server | 19888 | mapreduce.jobhistory.webapp.address | http 服务端口 |
| HBase | Master | 60000 | hbase.master.port | IPC |
| HBase | Master | 60010 | hbase.master.info.port | http 服务端口 |
| HBase | RegionServer | 60020 | hbase.regionserver.port | IPC |
| HBase | RegionServer | 60030 | hbase.regionserver.info.port | http 服务端口 |
| HBase | HQuorumPeer | 2181 | hbase.zookeeper.property.clientPort | HBase-managed ZK mode,使用独立的 ZooKeeper 集群则不会启用该端口。 |
| HBase | HQuorumPeer | 2888 | hbase.zookeeper.peerport | HBase-managed ZK mode,使用独立的 ZooKeeper 集群则不会启用该端口。 |
| HBase | HQuorumPeer | 3888 | hbase.zookeeper.leaderport | HBase-managed ZK mode,使用独立的 ZooKeeper 集群则不会启用该端口。 |
| Hive | Metastore | 9083 | /etc/default/hive-metastore 中 export PORT= |
|
| Hive | HiveServer | 10000 | /etc/hive/conf/hive-env.sh 中 export HIVE_SERVER2_THRIFT_PORT= |
|
| ZooKeeper | Server | 2181 | /etc/zookeeper/conf/zoo.cfg 中 clientPort= |
对客户端提供服务的端口 |
| ZooKeeper | Server | 2888 | /etc/zookeeper/conf/zoo.cfg 中 server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 | follower 用来连接到 leader,只在 leader 上监听该端口。 |
| ZooKeeper | Server | 3888 | /etc/zookeeper/conf/zoo.cfg 中 server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 | 用于 leader 选举的。只在 electionAlg 是 1,2 或 3(默认)时需要。 |
所有端口协议均基于 TCP。
对于存在 Web UI(HTTP 服务)的所有 hadoop daemon,有如下 url:
/logs
日志文件列表,用于下载和查看
/logLevel
允许你设定 log4j 的日志记录级别,类似于 hadoop daemonlog
/stacks
所有线程的 stack trace,对于 debug 很有帮助
/jmx
服务端的 Metrics,以 JSON 格式输出。
/jmx?qry=Hadoop:*会返回所有 hadoop 相关指标。
/jmx?get=MXBeanName::AttributeName 查询指定 bean 指定属性的值,例如/jmx?get=Hadoop:service=NameNode,name=NameNodeInfo::ClusterId 会返回 ClusterId。
这个请求的处理类:org.apache.hadoop.jmx.JMXJsonServlet而特定的 Daemon 又有特定的 URL 路径特定相应信息。
NameNode:http://:50070/
/dfshealth.jsp
HDFS 信息页面,其中有链接可以查看文件系统
/dfsnodelist.jsp?whatNodes=(DEAD|LIVE)
显示 DEAD 或 LIVE 状态的 datanode
/fsck
运行 fsck 命令,不推荐在集群繁忙时使用!
DataNode:http://:50075/
/blockScannerReport
每个 datanode 都会指定间隔验证块信息