花了一个星期,把 hadoop 整套算是搞通了,做这套 hadoop 是给 bi 做数据分析使用的,之前他们是用 MySQL cluster 来做数据查询,MySQL cluster 的好处是数据全部加载到内存中,查询会非常快,不足的地方是数据容量受限,内存多大,数据最多能放多少,所以我们新建设了一套 hadoop 集群。
搭建 hadoop 集群,我们使用的ambari组建,这套组建能够让你自由的组织和扩容 hadoop 集群,官网地址为:https://ambari.apache.org/ ,我安装了最新版本 2.2.0。
安装过程网上很多,这里给出我的安装清单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| Admin Name : admin
Cluster Name : BI_hadoop
Total Hosts : 5 (5 new)
Repositories:
debian7 (HDP-2.3):
https://public-repo-1.hortonworks.com/HDP/debian7/2.x/updates/2.3.4.0
debian7 (HDP-UTILS-1.1.0.20):
https://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/debian6
redhat6 (HDP-2.3):
https://public-repo-1.hortonworks.com/HDP/centos6/2.x/updates/2.3.4.0
redhat6 (HDP-UTILS-1.1.0.20):
https://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos6
redhat7 (HDP-2.3):
https://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.3.4.0
redhat7 (HDP-UTILS-1.1.0.20):
https://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos7
suse11 (HDP-2.3):
https://public-repo-1.hortonworks.com/HDP/suse11sp3/2.x/updates/2.3.4.0
suse11 (HDP-UTILS-1.1.0.20):
https://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/suse11sp3
ubuntu12 (HDP-2.3):
https://public-repo-1.hortonworks.com/HDP/ubuntu12/2.x/updates/2.3.4.0
ubuntu12 (HDP-UTILS-1.1.0.20):
https://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/ubuntu12
ubuntu14 (HDP-2.3):
https://public-repo-1.hortonworks.com/HDP/ubuntu14/2.x/updates/2.3.4.0
ubuntu14 (HDP-UTILS-1.1.0.20):
https://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/ubuntu12
Services:
HDFS
DataNode : 3 hosts
NameNode :hadoop1
NFSGateway : 0
host SNameNode :hadoop1
YARN + MapReduce2
App Timeline Server :hadoop1
NodeManager : 3 hosts
ResourceManager :hadoop1
Tez
Clients : 3 hosts
Hive
Metastore : hadoop1
HiveServer2 : ambari
WebHCat Server : ambari
Database : MySQL (New MySQL Database)
Pig
Clients : 3 hosts
Sqoop
Clients : 3 hosts
ZooKeeper
Server : ambari
Ambari Metrics
Metrics Collector : ambari
Spark
History Server : ambari
Thrift Server : 0 host
|
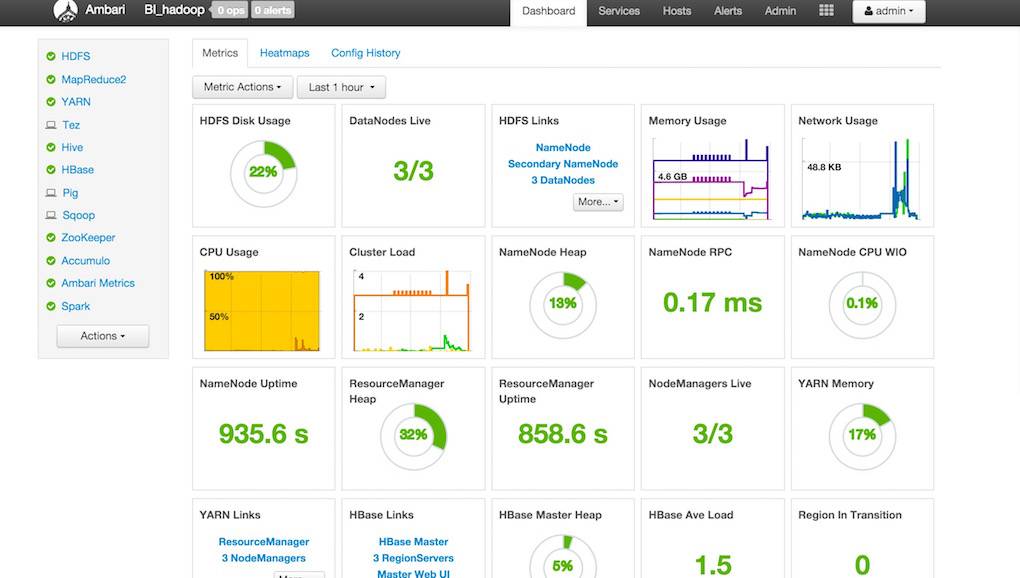
ambari 主页面如下:
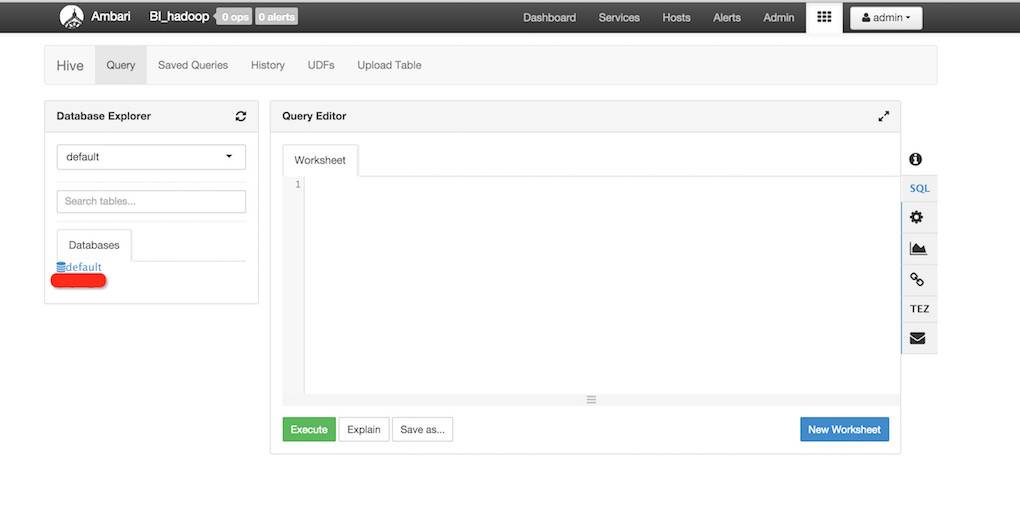
hadoop 的各项配置可以按照 ambari 给的参考配置设定,在 web 端即可实现 hive 接口查询数据:
数据录入我们是通过 MySQL 的 select into outfile 到 txt 文件,然后在 hive 中 load 到 hadoop 中,中间遇到一些坑,是 MySQL 一些字段的换行符,这个问题查看一下我的上一篇文章,在 hive 创建数据库表中,text 字段可以用 string 替代,*int(*)换成*int 即可。